redis面试问题复习
小伙子您好,看你简历上写了你项目里面用到了Redis,你们为啥用Redis?
心里忍不住暗骂,这叫啥问题,大家不都是用的这个嘛,但是你不能说出来。
认真回答道:帅气迷人的面试官您好,因为传统的关系型数据库如Mysql已经不能适用所有的场景了,比如秒杀的库存扣减,APP首页的访问流量高峰等等,都很容易把数据库打崩,所以引入了缓存中间件,目前市面上比较常用的缓存中间件有Redis 和 Memcached 不过中和考虑了他们的优缺点,最后选择了Redis。
至于更细节的对比朋友们记得查阅Redis 和 Memcached 的区别,比如两者的优缺点对比和各自的场景,后续我有时间也会写出来。
redis 和memcached的共同点:
1.都是基于内存的数据库,一般都用来当作缓存
2.都有过期策略
3.两者的性能都是非常好的
区别:
1.Redis支持更加丰富的数据类型(支持梗复杂的应用场景)redis不仅仅有简单的k/v的数据类型还有list,set,zset,hash等数据类型 但是memcached只支持最贱的k/v的数据类型
2.Redis支持数据的持久化,可以将内存中的数据保存到磁盘中,重启的时候可以再次加载并且使用,但是memcached只能将数据存储在内存中不能持久化
3.Redis有灾难恢复机制,因为可以把缓存的数据持久化到磁盘上
4.redis在服务器的内存使用完之后,有机制将不用的数据放到磁盘上,但是memcached在服务器内存使用完之后就直接报错
5.memcached没有原生的集群模式,但是redis目前是原生支持cluster模式的
redis支持发布订阅模型,lua脚本,事务等功能,但是memcached不支持,而且redis支持更多的编程语言
6.memcached只用了惰性删除过期的策略,但是redis同时使用了惰性删除和定期删除、
那小伙子,我再问你,Redis有哪些数据结构呀?
字符串String、字典Hash、列表List、集合Set、有序集合SortedSet。
String 的使用场景:
1.普通缓存
2.计数器 使用 incr key 三种情况 值不是整数返回错误 值是整数返回自增后的结果 key不存在先初始化为0返回1 比如文章的阅读量 视频的播放量都可以使用redis来计数,每播放一次次数加1,同时将这些数据异步的同步到数据当中实现持久化的目的
3.分布式锁 setnx key value 当key不存在的时候将key的值设成1 若key已经存在就不做任何动作返回0,如果返回1代表获取锁,做完操作 del key删除key 如果返回0代表获取锁失败
具体的使用场景:1.知乎每个问题的浏览器访问次数2.ip限制,为了安全考虑有些网站会对ip进行限制,同一ip在一定时间内访问的次数不可以超过n次
4.共享session 在分布式系统中用户的每次请求都发在不同的服务器上,这就会导致session不同步的问题,假如一个请求发到a服务器上,获取到用户信息后存入session中,下一个请求发在b上session就不可以正常的获取用户数据了,为了解决这个问题,就直接用redis集中管理这些session,将session存入redis,使用的时候获取就可以了
Hash
1.构建一个 用户表结构
id name age
1 何哥 15
list
列表存储的是有序的字符串两端都可以插入和弹出数据
1.做分页 lrange key 0 9
set无序集合自动去重
4.1、用户标签
例如一个用户对篮球、足球感兴趣,另一个用户对橄榄球、乒乓球感兴趣,这些兴趣点就是一个标签。有了这些数据就可以得到喜欢同一个标签的人,以及用户的共同感兴趣的标签。给用户打标签的时候需要①给用户打标签,②给标签加用户,需要给这两个操作增加事务。
给用户打标签
sadd user:1:tags tag1 tag2
给标签添加用户
sadd tag1:users user:1
sadd tag2:users user:1
使用交集(sinter)求两个user的共同标签
sinter user:1:tags user:2:tags
4.2、抽奖功能
集合有两个命令支持获取随机数,分别是:
随机获取count个元素,集合元素个数不变
srandmember key [count]
随机弹出count个元素,元素从集合弹出,集合元素个数改变
spop key [count]
用户点击抽奖按钮,参数抽奖,将用户编号放入集合,然后抽奖,分别抽一等奖、二等奖,如果已经抽中一等奖的用户不能参数抽二等奖则使用spop,反之使用srandmember。
zset
zset不允许重复的成员,redis还可以通过score来 从小到大排序天然就是用来做排行榜的
用户发布了n篇文章,其他人看到文章后给喜欢的文章点赞,使用score来记录点赞数,有序集合会根据score排行。流程如下
用户发布一篇文章a,初始点赞数为0,即score为0
zadd user:article 0 a
有人给文章a点赞,递增1
zincrby user:article 1 a
查询点赞前三篇文章
zrevrangebyscore user:article 0 2
查询点赞后三篇文章
zrangebyscore user:article 0 2
那你可以用zset实现简单的微信运动嘛
1.如果数据量不大的话其实直接用mysql中的order by 就可以进行排列了,如果查询满了就加索引,如果数据量大就分库分表
2.如果从更本上解决的话就要用redis使用sset 这个数据类型
语法结构是 key score member member不可以重复但是score可以换句话说就是可以有两个人是666步但是不可以有两个sam如果两个member的score相等就按照 lexicographically来排序字典排序
具体步骤:
1.1添加一个member
- zadd sport:ranking:20210227 10026 why
- zadd sport:ranking:20210227 10158 mx 30169 les 48858 skr 66079 jay
-
执行完之后的数字表示添加成功的member个数
在rdm中的样子
2.添加member的score
zincrby sport:ranking:20210227 5000 why
由于有用户的步数增加了按照score倒叙排列的顺序也就有了变化
3.获取member的排名
zrank 是按照分数从低到高返回 member 排名。
zrevrank 是按照分数从高到低返回 member 排名。
所以,在微信步数排行榜的这个需求中,步数越多排名越靠前,我们应该用 zrevrank。
4.获取在指定排名范围内的member
zrevrange sport:ranking:20210227 0 2
此时可以加上withscores返回member对应的score
获取所有人的排名
zrevrange sport:ranking:20210227 0 -1
5.保证每个人的redis的获取的微信好友的步数不同
我们当前的 key 是 sport:ranking:20210227,里面只包含了某一天的信息。只要我们在 key 里面加上用户的属性就可以了,假设我的微信号是 why。那么 key 可以设计为这样 sport:ranking:why:20210227。
对应添加用户的命令改成
- zadd sport:ranking:why:20210227 10026 why 10158 mx 30169 les 48858 skr 66079 jay
- zadd sport:ranking:mx:20210227 7688 赵四 9688 刘能 10026 why 10158 mx 54367 大脚
6.不仅仅获取我的步数和排名并且获取的微信头像和朋友圈点赞的数量
6.1使用hash的数据接口来存储每一天每个人都的数据
执行的命令是 hmset sport:ranking:why:20210227:jay nickName jay headPhoto xxx likeNum 520 walkNum 66079
6.2更新朋友圈点赞的数量就更行likenum
hincrby sport:ranking:why:20210227:jay likeNum 500
7,如果是要获取一个月一周一季度一年的数据并且做一个排行榜怎么做
用的是这个api:
zinterstore/zunionstore destination numkeys key key ...] [aggregate sum|min|max] 获取交集/并集
各个简历的意思是
- zinterstore/zunionstore其实就是交集/并集
- destination 将交集/并集的结果保存到这个键中
- numkeys 需要做交集/并集的集合的个数
- key [key ...] 具体参与交集/并集的集合
- weights weight [weight ...] 每个参与计算的集合的权重。在做交集/并集计算时,每个集合中的 member 会把自己的 score 乘以这个权重,默认为 1。
- aggregate sum|min|max 对于各个集合中的相同元素是 sum(求和)、min(取最小值)还是max(取最大值),默认为 sum。
添加七天的数据:
- zadd sport:ranking:why:20210222 43243 why 2341 mx 8764 les 42321 skr
- zadd sport:ranking:why:20210223 57632 why 24354 mx 4231 les 43512 skr 5341 jay
- zadd sport:ranking:why:20210224 10026 why 12344 mx 54312 les 34531 skr 43512 jay
- zadd sport:ranking:why:20210225 54312 why 32451 mx 23412 les 21341 skr 56321 jay
- zadd sport:ranking:why:20210226 3212 why 63421 mx 53652 les 45621 skr 5723 jay
- zadd sport:ranking:why:20210227 5462 why 10158 mx 30169 les 48858 skr 66079 jay
- zadd sport:ranking:why:20210228 43553 why 4451 mx 7431 les 9563 skr 8232 jay
tips:而且需要注意的是 20210222 这一天是没有 jay 的数据的
现在我们要看最近七天的数据排行榜
zunionstore sport:ranking:why:last_seven_day 7 sport:ranking:why:20210222 sport:ranking:why:20210223 sport:ranking:why:20210224 sport:ranking:why:20210225 sport:ranking:why:20210226 sport:ranking:why:20210227 sport:ranking:why:20210228 weights 1 1 1 1 1 1 1 aggregate sum
其中的aggregate和weights不用写有默认值
上面七天的是取得交集如果是七天都有参加跑步的排行榜就做并集
zinterstore sport:ranking:why:last_seven_day_zinterstore 7 sport:ranking:why:20210222 sport:ranking:why:20210223 sport:ranking:why:20210224 sport:ranking:why:20210225 sport:ranking:why:20210226 sport:ranking:why:20210227 sport:ranking:why:20210228 weights 1 1 1 1 1 1 1 aggregate sum
此时就没有jay同学了
如果数据量极大就要用桶的办法分流数据用分治的思想
这个桶可以是一个 Redis 里面的 8 个不同的 key,甚至可以是 8 个 Redis 里面各一个 key,看面试官给你的经费是多少,钱多就可劲造。
比如说王者的分级
王者一共 8 个段位:
- 1、倔强青铜
- 2、秩序白银
- 3、荣耀黄金
- 4、尊贵铂金
- 5、永恒钻石
- 6、至尊星耀
- 7、最强王者
- 8、荣耀王者
所以我们就放8个桶
解释一下上面的图片中 score 为 8588 是怎么来的。
首先我们用 Redis 的有序集合,那么我们就得给每个 member 一个 score。
所以,每个用户在桶里面都一个经过公式计算后得出的积分。
比如why哥现在的段位就是星耀,假设计算出来的分数是 8588。
那么现在要算why哥在全服的排名就很好算了:
写程序的时候是可以知道我现在的段位是星耀,那么直接去星耀的桶里面,用 zrevrank 计算出当前桶里面的排名,假设为 n。
然后再通过 zcard 这个 O(1) 的命令获取到,前面的桶,也就是最强王者和荣耀王者这两个桶的集合大小,分别为 y 和 x。
那么why哥的全服排名就是 n+y+x。
所以获取任何一个用户的全服排名,就是看他在自己的桶里面的排名加上前面桶里面的元素个数即可。
而且现在要计算全服 top 100 就很容易了嘛。
直接取最前面的桶,也就是荣耀王者里面的前 100 个就完事了。
搞定。
等等,真的搞定了吗?
思路是对了,但是对于亿级用户只分 8 个桶未免太少了吧?
那就继续分桶呗,别忘了,每个段位里面还有小段位的。
比如星耀,里面就有星耀五到星耀一五个小段位,青铜三到青铜一三个小段位。
全部算上就是 27 个桶。
但是,27 个桶也少。
那么星耀二到星耀一还需要五颗星、青铜三到青铜二要三颗星才行呢。
这样算下来,就是 160 个桶。
160 个桶还是不够?
额。。。
推翻重来,直接把段位加上各种其他条件换算成积分,然后按照积分来拆分:
这样,想怎么拆分数段都行、拆多细都行。
完美。
等等,真的完美吗?
你看我的积分范围,都划分的非常的均匀。
按照
段位拆分,有些菜鸡选手,打了两把觉得没意思,骂骂咧咧的退出游戏,就一直留在了青铜段位。
所以青铜段位的选手肯定是远大于荣耀王者的。
所以,实际情况下,用户的落点其实并不是均匀的。
怎么办?
这个时候就需要进行数据分析,通过一系列的高数、概率、离散等知识去做个桶大小的预估。
啊,这玩意就超纲了啊。
相关阅读:一口气说16个redis的常见使用场景
https://mp.weixin.qq.com/s/8BSeleLovCbZYILkyYKBwg
这里我相信99%的读者都能回答上来Redis的5个基本数据类型。如果回答不出来的小伙伴我们就要加油补课哟,大家知道五种类型最适合的场景更好。
但是,如果你是Redis中高级用户,而且你要在这次面试中突出你和其他候选人的不同,还需要加上下面几种数据结构HyperLogLog、Geo、Pub/Sub。
如果你还想加分,那你说还玩过Redis Module,像BloomFilter,RedisSearch,Redis-ML,这个时候面试官得眼睛就开始发亮了,心想这个小伙子有点东西啊。
注:本人在面试回答到Redis相关的问题的时候,经常提到BloomFilter(布隆过滤器)这玩意的使用场景是真的多,而且用起来是真的香,原理也好理解,看一下文章就可以在面试官面前侃侃而谈了,不香么?下方传送门 ↓
布隆过滤器
避免缓存击穿的利器之BloomFilter https://juejin.cn/post/6844903982209449991
布隆过滤器是用来检验一个元素是否在一个集合中的,他的优点是空间效率和查询时间都远远超过一般的算法,但是缺点是有一定的误识别率和删除困难
原理是,当一个元素 被加入集合时,通过k课散列函数映射出来的值,把布隆过滤器器中对应的位置设置成1,检索时骂我们就看这个元素通过散列函数算出来的位置是否都是1,如果都是1则可能存在,但是如果存在0则一定不存在
布隆过滤器和bit-map的区别是布隆过滤器使用了k个哈希函数,每个字符串和k个bit对应,从而降低了冲突的概率
那么布隆过滤器有
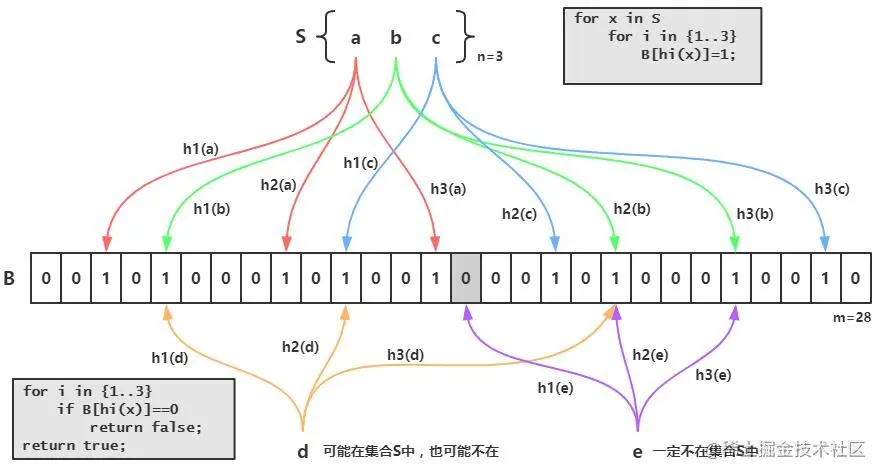
那布隆过滤器实际中有什么作用呢
简单说就是先将我们的数据加载到布隆过滤器中,防止缓存击穿,如果请求数据在过滤器中不存在则直接返回不到数据阶段,解决了可能存在的缓存击穿风险
Bloom Filter的缺点
1.存在误判,可能要查到的元素并没有在容器中,但是hash之后得到的k个位置上值都是1。如果bloom filter中存储的是黑名单,那么可以通过建立一个白名单来存储可能会误判的元素。
删除困难。一个放入容器的元素映射到bit数组的k个位置上是1,删除的时候不能简单的直接置为0,可能会影响其他元素的判断。可以采用Counting Bloom Filter
作者:敖丙
链接:https://juejin.cn/post/6844903982209449991
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
简单的应用代码
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>
package BloomFilter;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
/**
* 测试布隆过滤器(可用于redis缓存穿透)
*
* @author 敖丙
*/
public class TestBloomFilter {
private static int total = 1000000;
private static BloomFilter<Integer> bf = BloomFilter.create(Funnels.integerFunnel(), total);
// private static BloomFilter<Integer> bf = BloomFilter.create(Funnels.integerFunnel(), total, 0.001);
public static void main(String[] args) {
// 初始化1000000条数据到过滤器中
for (int i = 0; i < total; i++) {
bf.put(i);
}
// 匹配已在过滤器中的值,是否有匹配不上的
for (int i = 0; i < total; i++) {
if (!bf.mightContain(i)) {
System.out.println("有坏人逃脱了~~~");
}
}
// 匹配不在过滤器中的10000个值,有多少匹配出来
int count = 0;
for (int i = total; i < total + 10000; i++) {
if (bf.mightContain(i)) {
count++;
}
}
System.out.println("误伤的数量:" + count);
}
}
误伤的数量:320
运行结果表示遍历一百万个在过滤器中的数时都识别出来了,但是一万个不再过滤器中的数误伤了320个错误率在0.03左右
不过我们可以设置错误率
BloomFilter一共四个create方法,不过最终都是走向第四个。看一下每个参数的含义:
funnel:数据类型(一般是调用Funnels工具类中的)
expectedInsertions:期望插入的值的个数
fpp 错误率(默认值为0.03)
strategy 哈希算法(我也不懂啥意思)Bloom Filter的应用
错误率降低相应的空间消耗的就越多看需求如何取舍
常见的几个应用场景:
cerberus在收集监控数据的时候, 有的系统的监控项量会很大, 需要检查一个监控项的名字是否已经被记录到db过了, 如果没有的话就需要写入db.
爬虫过滤已抓到的url就不再抓,可用bloom filter过滤
垃圾邮件过滤。如果用哈希表,每存储一亿个 email地址,就需要 1.6GB的内存(用哈希表实现的具体办法是将每一个 email地址对应成一个八字节的信息指纹,然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email地址需要占用十六个字节。一亿个地址大约要 1.6GB,即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB的内存。而Bloom Filter只需要哈希表 1/8到 1/4 的大小就能解决同样的问题。
作者:敖丙
链接:https://juejin.cn/post/6844903982209449991
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
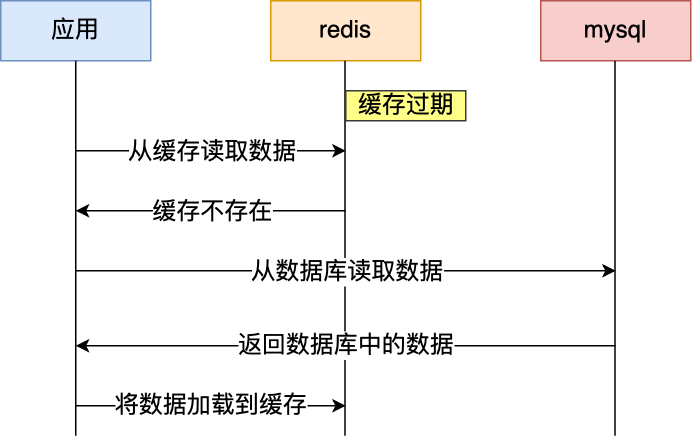
如果有大量的key需要设置同一时间过期,一般需要注意什么?
如果大量的key过期时间设置的过于集中,到过期的那个时间点,redis可能会出现短暂的卡顿现象。严重的话会出现缓存雪崩,我们一般需要在时间上加一个随机值,使得过期时间分散一些。
电商首页经常会使用定时任务刷新缓存,可能大量的数据失效时间都十分集中,如果失效时间一样,又刚好在失效的时间点大量用户涌入,就有可能造成缓存雪崩
redis过期有两个策略
1.定期删除: redis默认时100ms就随机抽取一些设置了过期时间的key,检查他是否过期,如果过期了就直接删除,但是这个策略不能保证所有的过期的key都删除了
2.惰性删除: 在客户端获取某个key时,redis首先对其进行检查,若是这个key过期了就删除掉
实际操作中将两个策略相结合
那你使用过Redis分布式锁么,它是什么回事?
先拿setnx来争抢锁,抢到之后,再用expire给锁加一个过期时间防止锁忘记了释放。
这时候对方会告诉你说你回答得不错,然后接着问如果在setnx之后执行expire之前进程意外crash或者要重启维护了,那会怎么样?
这时候你要给予惊讶的反馈:唉,是喔,这个锁就永远得不到释放了。紧接着你需要抓一抓自己得脑袋,故作思考片刻,好像接下来的结果是你主动思考出来的,然后回答:我记得set指令有非常复杂的参数,这个应该是可以同时把setnx和expire合成一条指令来用的!
对方这时会显露笑容,心里开始默念:嗯,这小子还不错,开始有点意思了。
假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如何将它们全部找出来?
使用keys指令可以扫出指定模式的key列表
获取所有Key命令:redis-cli keys ‘*’ ;
获取指定前缀的key:redis-cli KEYS “edu:*”
对方接着追问:如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
这个时候你要回答redis关键的一个特性:redis的单线程的。keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长。
不过,增量式迭代命令也不是没有缺点的: 举个例子, 使用 SMEMBERS 命令可以返回集合键当前包含的所有元素, 但是对于 SCAN 这类增量式迭代命令来说, 因为在对键进行增量式迭代的过程中, 键可能会被修改, 所以增量式迭代命令只能对被返回的元素提供有限的保证
使用过Redis做异步队列么,你是怎么用的?
一般使用list结构作为队列,rpush生产消息,lpop消费消息。当lpop没有消息的时候,要适当sleep一会再重试
如果对方追问可不可以不用sleep呢?
list还有个指令叫blpop,在没有消息的时候,它会阻塞住直到消息到来
如果对方接着追问能不能生产一次消费多次呢?
使用pub/sub主题订阅者模式,可以实现 1:N 的消息队列
如果对方继续追问 pub/su b有什么缺点?
在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如RocketMQ等
如果对方究极TM追问Redis如何实现延时队列?
这一套连招下来,我估计现在你很想把面试官一棒打死(面试官自己都想打死自己了怎么问了这么多自己都不知道的),如果你手上有一根棒球棍的话,但是你很克制。平复一下激动的内心,然后神态自若的回答道:使用sortedset,拿时间戳作为score,消息内容作为key调用zadd来生产消息,消费者用zrangebyscore指令获取N秒之前的数据轮询进行处理
到这里,面试官暗地里已经对你竖起了大拇指。并且已经默默给了你A+,但是他不知道的是此刻你却竖起了中指,在椅子背后。
Redis是怎么持久化的?服务主从数据怎么交互的?
RDB做镜像全量持久化,AOF做增量持久化。因为RDB会耗费较长时间,不够实时,在停机的时候会导致大量丢失数据,所以需要AOF来配合使用。在redis实例重启时,会使用RDB持久化文件重新构建内存,再使用AOF重放近期的操作指令来实现完整恢复重启之前的状态。
这里很好理解,把RDB理解为一整个表全量的数据,AOF理解为每次操作的日志就好了,服务器重启的时候先把表的数据全部搞进去,但是他可能不完整,你再回放一下日志,数据不就完整了嘛。不过Redis本身的机制是 AOF持久化开启且存在AOF文件时,优先加载AOF文件;AOF关闭或者AOF文件不存在时,加载RDB文件;加载AOF/RDB文件城后,Redis启动成功; AOF/RDB文件存在错误时,Redis启动失败并打印错误信息
简述Redis的AOF
AOF叫做增量持久化 AOF通过日志,对数据的写入操作进行记录,这种持久话的操作实时性更好
简述AOF的持久化策略
1.always 没执行一次数据修改命令就将命令写入到磁盘日志文件
2.everysec 每秒将命令写入到磁盘日志文件上
3.no 不主动设置,由操作系统决定什么时候写入到磁盘的日志文件上
RDB与AOF优缺点比较
AOF占用的文件体积比RDB大,一般来说利用AOF备份对系统的消耗比RDB低,如果备份的时候出现故障,RDB数据可能全部丢失,但是AOF可能丢失一部分 但是RDB的回复速度比AOF快
RDB和AOF各有优缺点:
RDB持久化
优点:RDB文件紧凑,体积小,网络传输快,适合全量复制;恢复速度比AOF快很多。当然,与AOF相比,RDB最重要的优点之一是对性能的影响相对较小。
缺点:RDB文件的致命缺点在于其数据快照的持久化方式决定了必然做不到实时持久化,而在数据越来越重要的今天,数据的大量丢失很多时候是无法接受的,因此AOF持久化成为主流。此外,RDB文件需要满足特定格式,兼容性差(如老版本的Redis不兼容新版本的RDB文件)。
AOF持久化
与RDB持久化相对应,AOF的优点在于支持秒级持久化、兼容性好,缺点是文件大、恢复速度慢、对性能影响大。
作者:公众号_码农富哥
链接:https://juejin.cn/post/6844904196324458504
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
对方追问那如果突然机器掉电会怎样?
取决于AOF日志sync属性的配置,如果不要求性能,在每条写指令时都sync一下磁盘,就不会丢失数据。但是在高性能的要求下每次都sync是不现实的,一般都使用定时sync,比如1s1次,这个时候最多就会丢失1s的数据。
对方追问RDB的原理是什么?
你给出两个词汇就可以了,fork和cow。fork是指redis通过创建子进程来进行RDB操作,cow指的是copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。
注:回答这个问题的时候,如果你还能说出AOF和RDB的优缺点,我觉得我是面试官在这个问题上我会给你点赞,两者其实区别还是很大的,而且涉及到Redis集群的数据同步问题等等。想了解的伙伴也可以留言,我会专门写一篇来介绍的。
简述redis自动触发RDB的机制
1.通过配置文件,设置一定时间内自动执行RDB
2.如果在主从复制过程中自动执行RDB
3.redis shutdown的时候如果AOF没有开启会执行RDB
配置文件里可以配置像 save 900 1 save 300 10 save 60 100000 表示900s内要是有一条是写入命令就触发一次快照可以理解为一次备份save 300 10 表示要是300s内要是有10条写入就进行一次快照 还可以选择rdbcompression yes 配置受否压缩rdb文件,要是开启的话会增加cpu的消耗 rdbchecksum yes 可以在写入和读取文件的时候检验文件,关闭的话可以增加10%的性能但是数据损坏的时候就无法发现
说说说redis的save手动设置rdb
save命令是向redis server发送请求持久化的命令,由于redis是单线程的一个主线程来处理所有的请求,save命令会阻塞redis server处理其他的请求直到数据同步完成,save命令会阻塞redis服务器进程,直到EDB文件常见完毕位置,zairedis服务器阻塞期间,服务器不能处理任何请求,所以不建议在线上环境使用
那不建议用save可以用什么呢
可以使用bgsave方法,和save方法不一样bgsave方法是异步执行的,在执行bgsave命令之后,redis主进程会fork一个子进程将数据保存在RDB文件中,同步数据完之后对原有文件进行替换,然后通知主进程同步完成
对于redis的持久化有什么好的方法嘛
如果Redis中的数据并不是特别敏感或者可以通过其它方式重写生成数据,可以关闭持久化,如果丢失数据可以通过其它途径补回;
自己制定策略定期检查Redis的情况,然后可以手动触发备份、重写数据;
单机如果部署多个实例,要防止多个机器同时运行持久化、重写操作,防止出现内存、CPU、IO资源竞争,让持久化变为串行;
可以加入主从机器,利用一台从机器进行备份处理,其它机器正常响应客户端的命令;
RDB持久化与AOF持久化可以同时存在,配合使用
作者:公众号_码农富哥
链接:https://juejin.cn/post/6844904196324458504
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
什么是PipLine
通俗点:pipeline就是把一组命令进行打包,然后一次性通过网络发送到Redis。同时将执行的结果批量的返回回来
Pipeline有什么好处,为什么要用pipeline?
可以将多次IO往返的时间缩减为一次,前提是pipeline执行的指令之间没有因果相关性。使用redis-benchmark进行压测的时候可以发现影响redis的QPS峰值的一个重要因素是pipeline批次指令的数目。
Redis的同步机制了解么?
Redis可以使用主从同步,从从同步。第一次同步时,主节点做一次bgsave,并同时将后续修改操作记录到内存buffer,待完成后将RDB文件全量同步到复制节点,复制节点接受完成后将RDB镜像加载到内存。加载完成后,再通知主节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程。后续的增量数据通过AOF日志同步即可,有点类似数据库的binlog。
是否使用过Redis集群,集群的高可用怎么保证,集群的原理是什么?
Redis Sentinal着眼于高可用,在master宕机时会自动将slave提升为master,继续提供服务。
Redis Cluster着眼于扩展性,在单个redis内存不足时,使用Cluster进行分片存储。
redis有哪些集群部署方式
1.主从复制
2.哨兵模式
3.Cluster集群模式
你能讲讲这几个集群模式吗
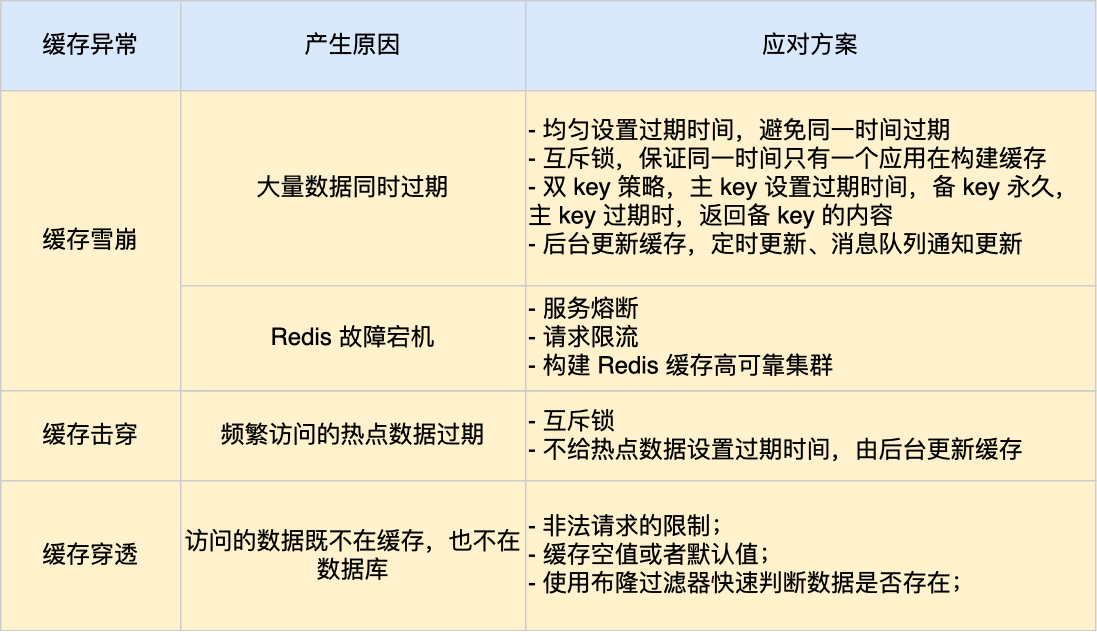
能讲讲什么是缓存雪崩
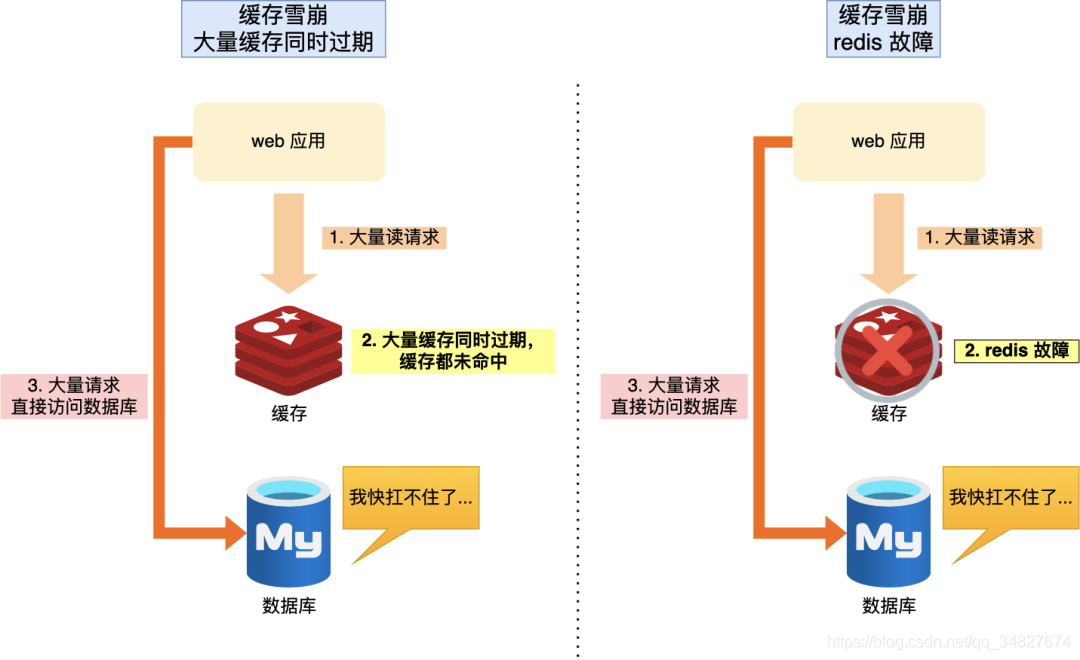
此时缓存雪崩是指缓存中一大批数据到期时间而从缓存中删除,但查询这这批数据量非常大,全部走数据库,造成数据库的压力过大造成系统崩溃
还有一种可能是redis故障宕机
redis缓存雪崩的解决办法
如果是过期时间的问题的话:
1.给数据的过期时间上加上一个随机数,保障大量数据不会再同一时间过期
2.加一个互斥锁 如果业务请求发现数据不在redis内就加上互斥锁,保证在同一时间内只有一个请求来构建缓存(从数据库中读取数据在写到redis里面) 当缓存完成后释放锁,未能获取互斥锁请求的就选择等待锁释放或者返回空值,再加上互斥锁的同时应该加上一个过期时间,以防阻塞
3.如果数据时热点数据的话可以不设置过期时间,不设置过期时间不代表这个数据不会消失,redis内存有自己清理数据的方式,或者可以单独开一个后台更新线程,后台更新数据
如果是redis服务宕机了
1.可以采用服务熔断或者是限流机制,暂停业务对缓存服务的访问直接返回错误,等到redis恢复正常了再使用缓存 为了减少对业务的影响可以采用请求限流的机制,只是将少部分请求发给数据库处理,等到redis恢复正常并且将缓存预热后,再接除限流机制
2.可以搭建redis缓存高可靠集群 ,如果redis主节点宕机了,可以将主节点切换成主节点并且继续提供缓存服务
你知道缓存预热吗?
在业务刚上线的时候先吧数据缓存起来,而不是等用户来访问才出发缓存构建
那你知道什么是缓存击穿嘛
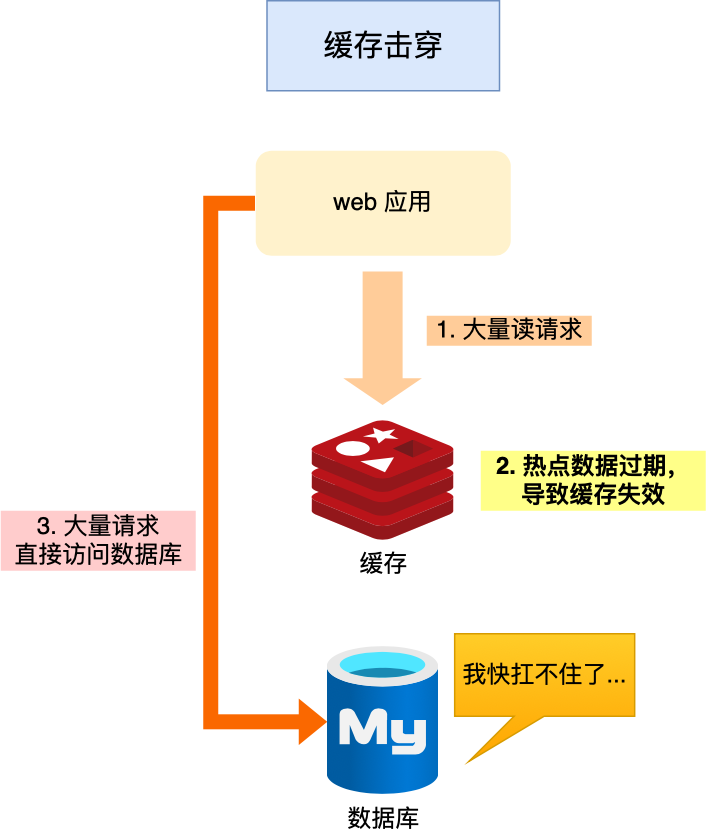
如果某个热点数据比如说秒杀活动,此时有大量数据访问了该热点数据,就无法再缓存中读取直接访问数据库,就容易被高并发请求冲垮这就是缓存击穿问题
其实缓存击穿就是缓存雪崩的一个子集,一个经常发生的情况
那缓存击穿你有什么解决方案嘛
1.设置互斥锁,保证同一时间只能有一个业务线程更新缓存,如果未能获得互斥锁的请求,要么等待所释放后重新读取缓存,要么就返回空值或者默认值
2.不给热点数据设置过期时间,后台异步更新热点数据,或者热点数据将要过期的时候,提前通知后台线程更新缓存和设置新的过期时间
那你知道什么是缓存穿透嘛
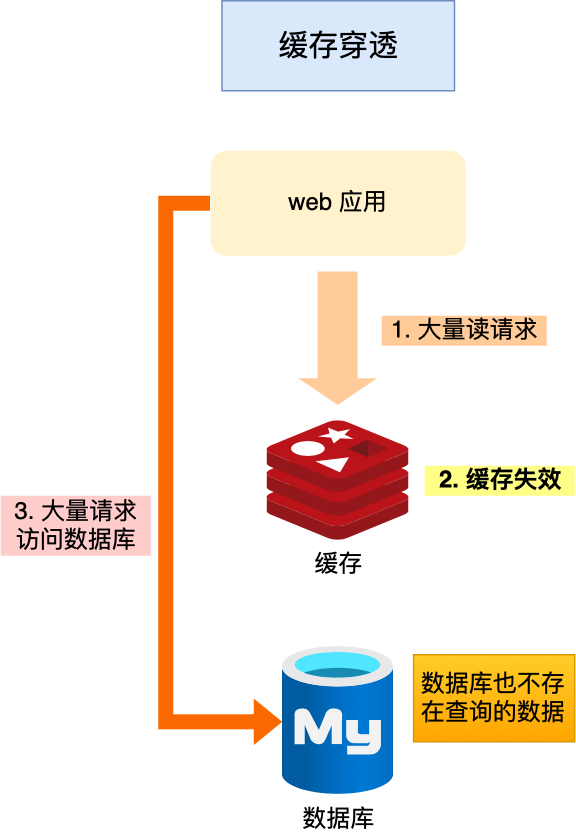
如果用户访问的数据即不再数据库当中也不在redis当中就会大量请求打在数据库上,数据库压力一下就大了不少
对于缓存穿透你有什么方法嘛
一般这样的有两个情况
1,一个是业务操作问题,缓存中的数据和数据库中的数据都被删除了
2.黑客的恶意攻击
应对方法:
1.对于非法请求的限制,在api的入口我们就要判断参数是否合理,如果不合理就直接返回错误,避免访问缓存和数据库
2.缓存一些空值或者默认值。线上的时候可以读取到空值或者默认值,而不会继续查询数据库
3.使用布隆过滤器
更新redis和数据库请问先更新哪个?
先更新数据库,再更新缓存

先更新redis后更新数据库

无论是先更新数据库还是先更新缓存,在并发的时候都存在数据不一致的情况
那你是用什么方式来解决缓存和数据库的更新问题呢
先删除缓存,再更新数据库

先更新数据库再删除缓存

两者也都有可能出现不一致情况,但是在实际中由于换缓存的写入是远快于数据库的写入的,所以在实际中很难出现请求b已经更新了数据库之后请求a才更新的情况 而一旦a请求早于b删除缓存,那么接下来的请求就会因为缓存不命中而从数据库中重新读取数据不会村子啊不一致的情况
所以先更新数据库再删除缓存的方案是可以保证数据一致性 并且可以加上过期时间
但是更新数据库和删除缓存是两个操作可能删除缓存失败了不就又不一致了嘛
问题的图像

1.使用重试机制

重试机制 :
1.引入消息队列将第二个操作删除加入到消息队列,如果消息队列缓存失败就从消息队列重新数据数据再删除缓存,如果重试超过一定次数都没有成功,就需要向业务层发送报错信息
2.如果缓存成功,就把数据从消息队列中移除避免重复操作
2.订阅mysql binlog 再更新缓存

我们可以订阅mysql binlog日志拿到具体要操作的数据再执行删除缓存这些操作都是异步的
分布式锁你了解嘛
为什么redis要哨兵机制
哨兵机制:它的主要作用是实现主从节点的故障转移。他会监控主节点是否还存活,如果发现主节点挂了,就选取一个从节点来切换成主节点,并且把新主节点相关信息通知给从节点和客户端
如何判断主节点是否真的故障了
哨兵模式下是哨兵会每隔1s给所有的主从节点发送ping命令,当主从节点收到ping命令后会返回一个命令给哨兵 以此来判断节点是否是在正常运行
如果在规定的时间内没有主从节点相应哨兵的ping命令,哨兵球会标记他们为主观下线,这个规定时间的配置项是down-after-milliseconds 单位是毫秒
那你能讲讲客观下线吗
因为简单就靠主观下线容易有误判的情况,比如说主节点的系统压力比较大或者网络发送了拥塞导致主节点没有在规定时间内返回响应ping命令
所以在部署哨兵的时候就不能只部署一个节点而是要用多个节点部署成哨兵集群,通过哨兵集群一起做判断来避免单个哨兵因为自身网络不好而误判主观下线的情况。
那么怎么判定主节点客观下线
当这几个哨兵的赞同票数量超过配置文件当中的quorum配置项设定的值后,这时主节点就会被哨兵标记为客观下线
比如说:有三个哨兵,quorum的数量是2,那么只要哨兵的赞成票大于等于2就可以标记主节点客观下线了,这两张表可以是自己本身和其他两个哨兵的赞成票
quorum值一般设计成哨兵数量的二分之一加1,例如三个哨兵就设置成2

由哪个哨兵进行主从故障转移
哨兵要在集群中选出一个leader,再选出leader之前首先要选出一个候选人,候选人就是哪个提出的主节点应该客观下线那么哪个哨兵就算为候选人,哨兵a在认为一个主节点主观下线后,就会给其他实例发送is-master-down-by-addr 命令,接着其他的哨兵会根据自己和主节点之间的网络情况做出投赞成票和反对票的响应
当哨兵a首都奥的赞成票满足绍哨兵配置文件quorum的值后就会将主节点标记为客观下线,此时哨兵a就是候选人
此时候选者会向其他哨兵发出命令,表示希望成为leader来实现主从切换,并让所有的哨兵进行投票
每个哨兵只有一次投票的机会,用完之后就不可以投票了,可以投给自己或给别人但是只有候选人可以投票给自己
在整个候选人投票的环节任何一个候选者必须满足下面的条件才可以成为leader
1.拿到半数以上的赞成票
2.拿到赞成票的票数大于等于哨兵配置文件当中的quorum值
举个例子 假如哨兵节点有三个,quorum值为2 ,其中一个候选人获得了两票那么他获得了半数以上的票数并且大于等于quorum值那么这个候选人就可以选举成功,不然就要重新进行选举
如果同时有两个哨兵发现了主线程的主观下线,那么此时就有两个候选者,然后向其他哨兵发起请求,如果此时哨兵a先得到了其他哨兵的赞同票,那么哨兵b会收到剩下那个哨兵的拒绝投票命令,此时哨兵a获得了两票符合主从故障转移的要求
如果只有两个哨兵形成集群的话吗,如果一个哨兵挂了,此时发生了主节点的主管下线,那么此时哨兵想成为leader就只能拿到1票无法完成主从切换
如果是三个哨兵挂了两个就要认为介入或者是增加哨兵的数量
所以quorum的值建议设置成哨兵个数的二分之一加1,并且哨兵个数应该是奇数

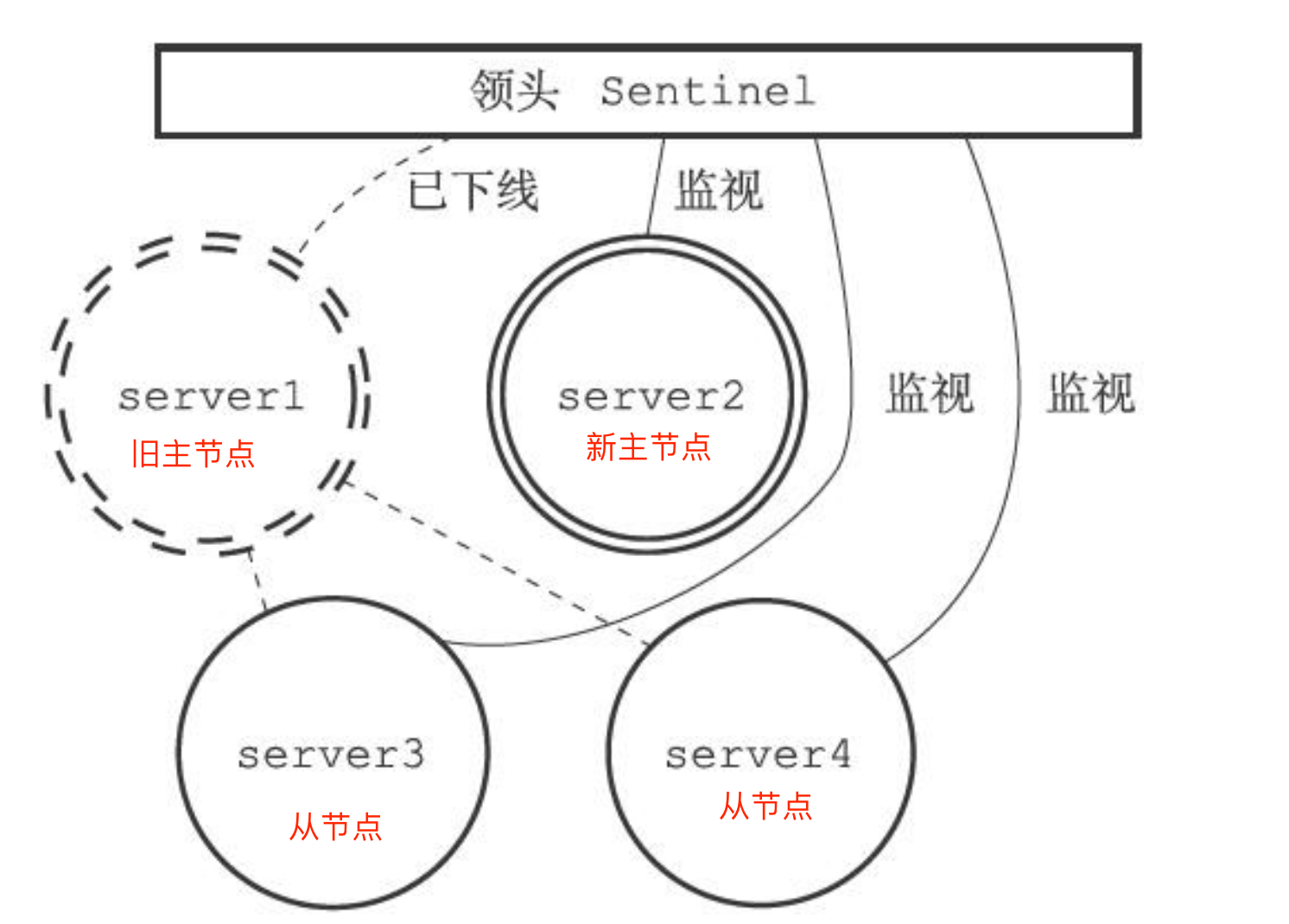
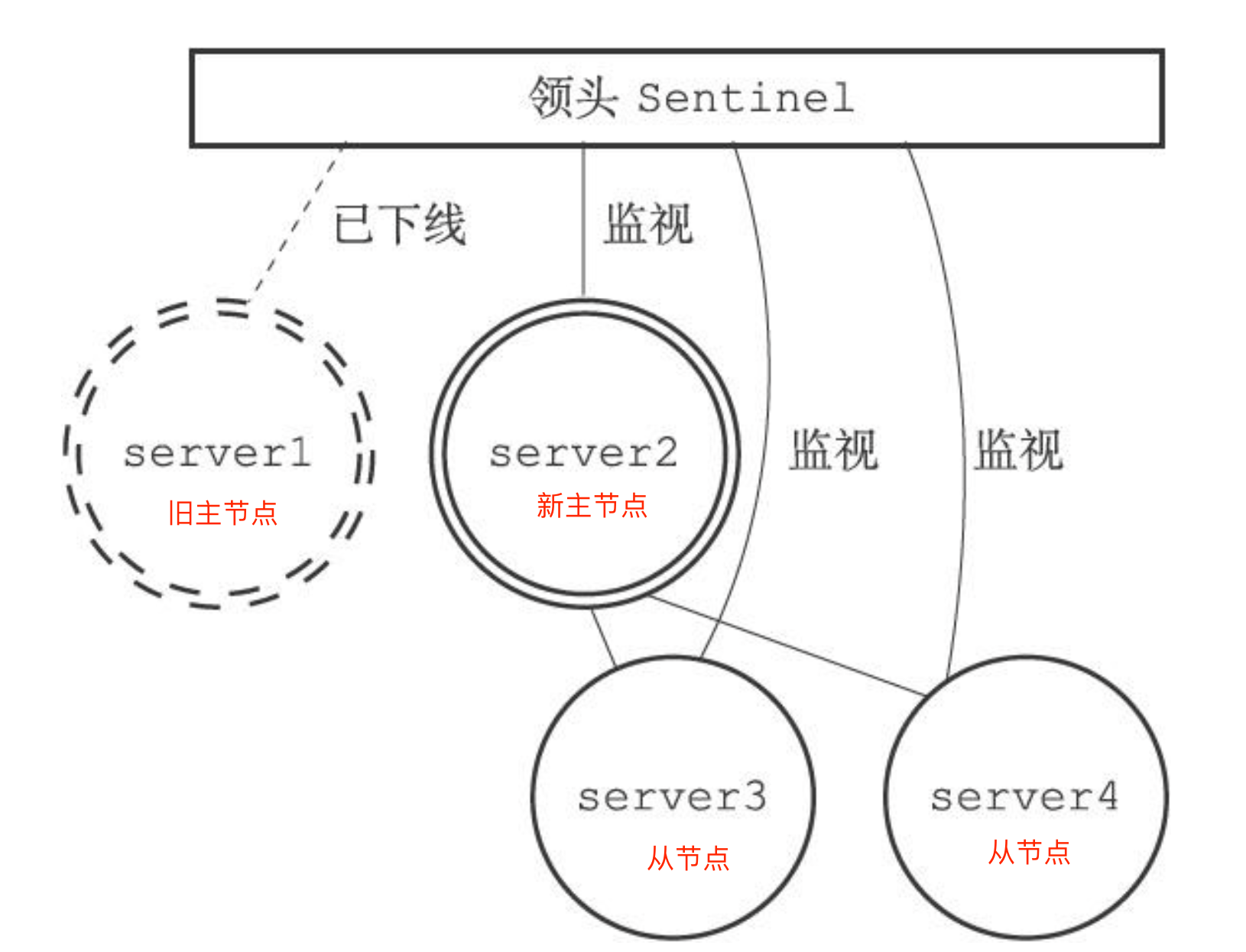
主从故障转移的过程是怎样的?
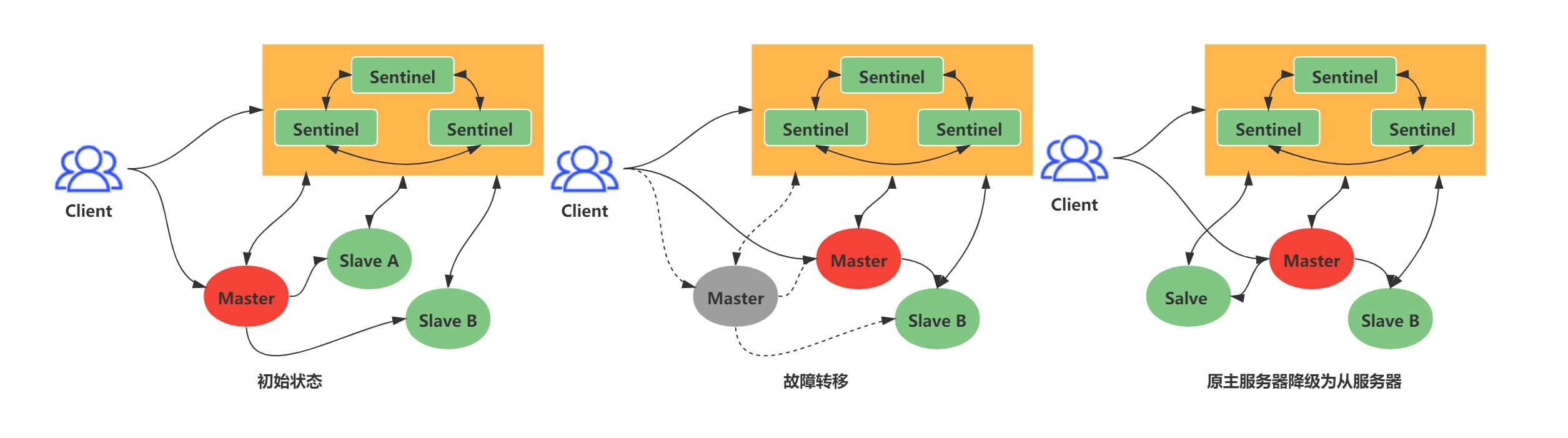
主从故障转移由四个过程
1.从旧主节点属下的从节点中挑选一个较好的从节点,将其转换为主节点
2.将剩下的从节点连接到新的主节点
3.将新主节点的ip地址和信息通过发布者/订阅者通知给客户端
4.继续监视老的主节点,当主节点重新上线的时候将主节点设置成新的主节点的从节点
步骤一:找出新的主节点
首先我们需要将网络状态不好的从节点过滤掉 redis有一个叫down-after-milliseconds * 10 配置项,其down-after-milliseconds 是主从节点断连的最大连接超时时间。如果在 down-after-milliseconds 毫秒内,主从节点都没有通过网络联系上,我们就可以认为主从节点断连了。如果发生断连的次数超过了 10 次,就说明这个从节点的网络状况不好,不适合作为新主节点。
然后我们从优先级,复制进度,和id号来判断哪个从节点最适合成为新主节点
第一轮考察:优先级最高的从节点胜出
Redis 有个叫 slave-priority 配置项,可以给从节点设置优先级。
如果a从节点是所有节点中物理内存最大的那么我们就可以将a从节点设置成优先级最高的
第二轮考察: 复制进度最靠前的从节点胜出
在主从架构中,主节点会将写入操作同步给从节点,在这个过程中,主节点会用master_repl_offset记录当前的操作在repl——backlog——buffer的位置,而从节点会用slave——repl——offset这个值记录当前的复制进度,如果某个从节点的slave_repl_offset最接近master_repl_offset那么就选择这个从节点为主节点
第三轮考察: id号小的胜出
每个节点都有一个id号作为唯一表示

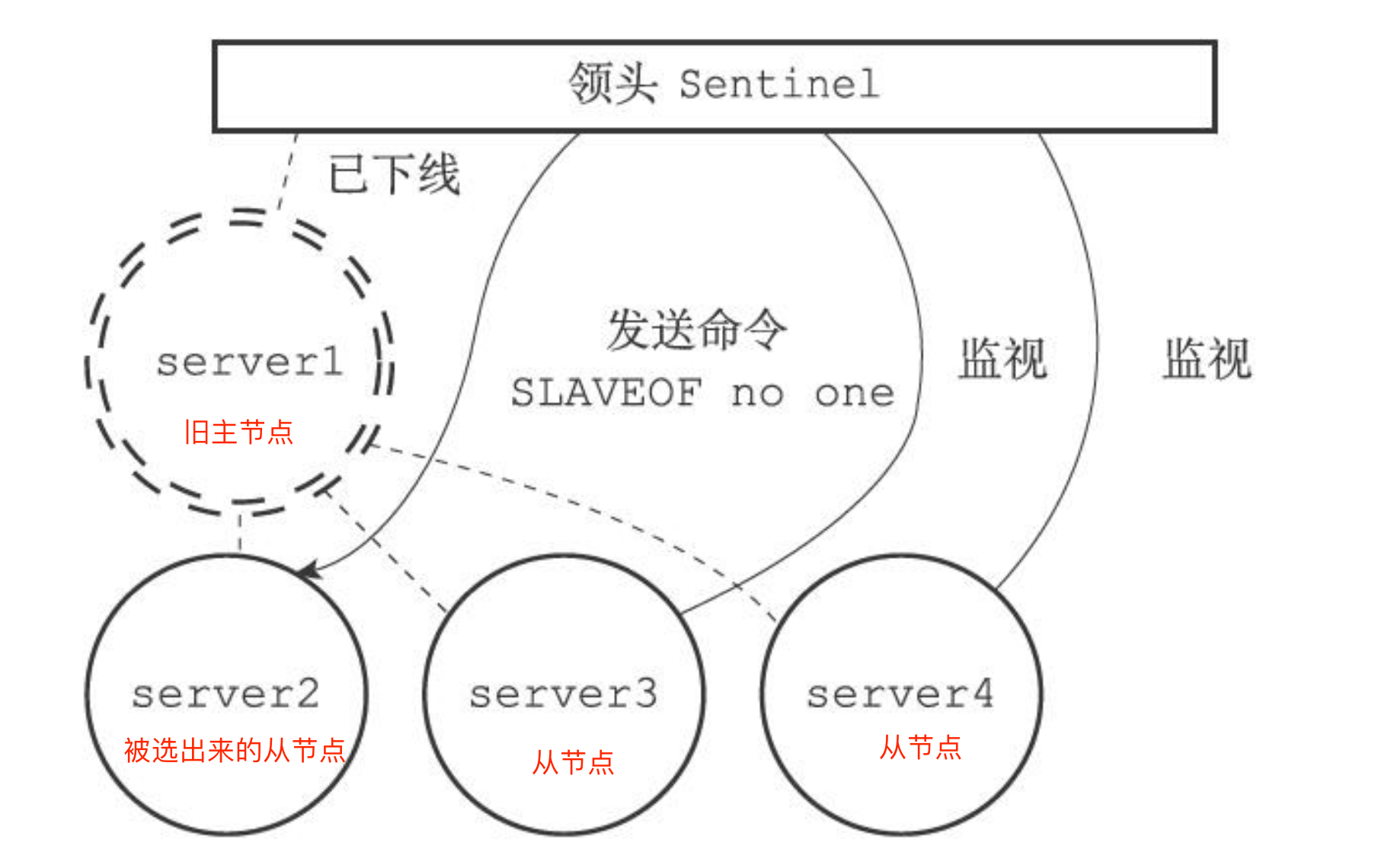
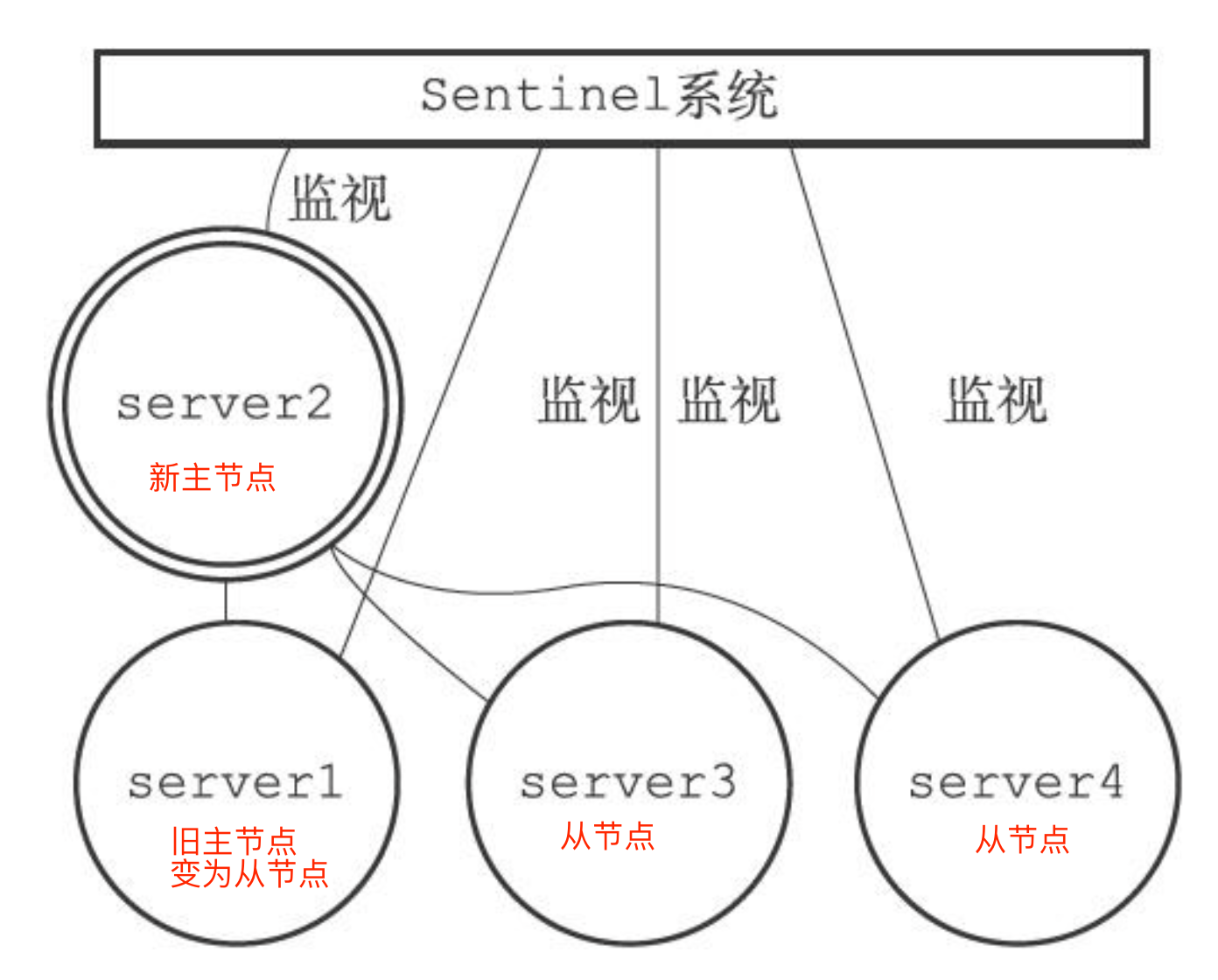
选出新的主节点后,哨兵向选中的从节点发送slave of no one 的命令让这个从节点接触从节点身份,将其变为新的主节点,在发送slaveof no one命令之后哨兵leader会向新的主节点fasonginfo命令并且是每十秒一次,并观察回复中的角色星系,当从节点顺利从从节点升级成为master主节点时,哨兵leader就知道被选中的从系欸但已经顺利变成新的主节点
之后向剩下的从节点发送slaveof的命令,让他们成为新的主节点的从节点
主从切换之后,哨兵会向+switch-master频道发布新主节点的ip地址和端口信息,这个时候客户端就可以接收到这一条消息,然后就可以用这里面的新主节点的ip地址和端口进行通信了
最后当旧主节点重新上线的时候,哨兵会给旧主节点发送slaveof的命令让他成为新主节点的从节点


redis为什么要有主从复制
主从复制的出现原因是,如果所有的文件都在一台机器上的话,如果这台机器发生宕机,由于数据恢复是要时间的所以在这个期间由于redis是单线程的,所以不能提供新的服务 如果这台服务器的硬盘出问题了,可能数据就都丢失了
避免这种单点故障最好的办法是将数据备份到其他的服务器上,让这些服务器也向外界接受请求提供服务,如果一台服务器宕机了出现故障了,其他服务器也可以继续提供服务
redis是怎么实现主从复制的呢
所有的数据的修改操作都是只在主服务器上进行,然后将新的数据同步给从服务器
第一次同步:
首先确定哪一台机器为主服务器
#在服务器b上执行这条命令
replicaof <服务器A的ip地址> <服务器A的redis端口号>
第一阶段:建立连接,协商同步
在执行了replicaof,命令后,从服务器就会给主服务器发送一个psync命令来表示希望实现数据同步
psync包括两个参数:代表主服务器的runid和复制进度offset
runid:是每个服务器的随机id来标识自己的,第一次同步时因为从节点不知道主服务器的id所以写?
offset:第一次同步时其值为-1
主服务器收到psync命令后返回一个fullresymc作为响应命令给对方,并且这个相应带着连个参数主服务器的runid和offset,从服务器收到后会保存记录两个值
fullresymc代表是用全量复制也就是主服务器会把所有数据同步给从服务器 所以第一阶段的所有工作都是为了全量复制做准备
第二阶段:主服务器同步数据给从服务器
主服务器会执行bgsave命令来生成rdb文件,然后将文件发送给服务器,从服务器收到文件后,会先清空当前的数据然后载入rdb文件,这里要注意因为主线程执行的时bgsave命令所以主线程是不堵塞的也就是说redis还是可以正常处理命令,如果在服务器生成rdb的过程中由命令操作,会将命令写入到 replication buffer缓冲区
第三阶段:主服务器发送新的写操作命令到从服务器
在主服务器将rdb文件发送给从服务器后,然后将replication buffer缓存区的紫萼操作发送给从服务器,从服务器再执行这些操作
在第一次建立了连接之后双方之间就会有一个tcp连接,而且这个是一个长连接目的是减少频繁tcp连接和断开所带来的性能开销
那请问主服务器rdb中占用网络宽带和cpu太久怎么办
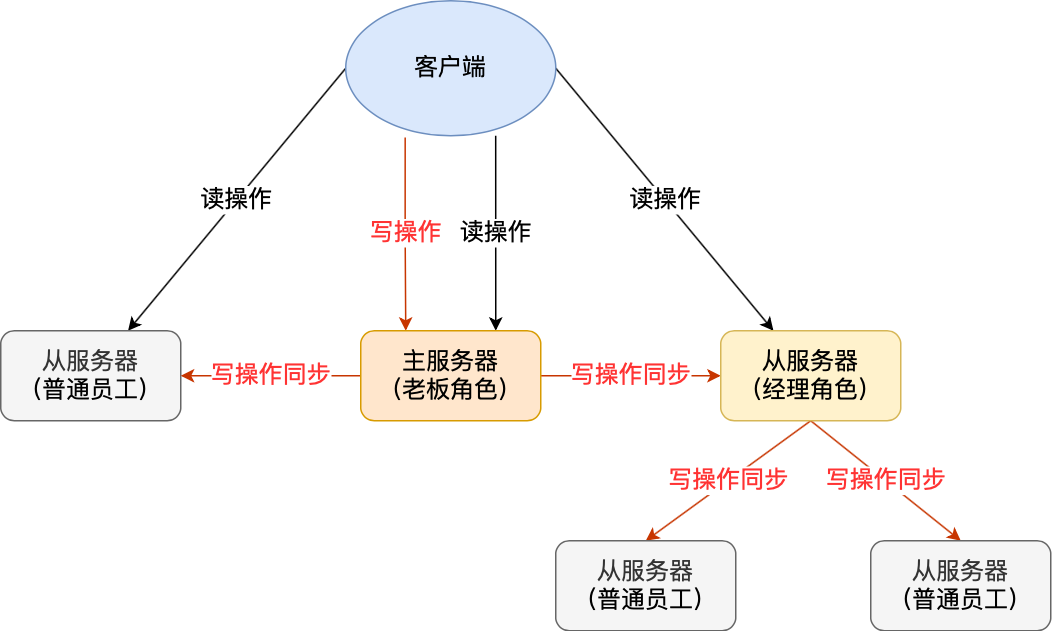
redis可以让从服务器也有自己的从服务器,拥有从服务器的从服务器成为经理角色,自己可以接受主服务器二点同步数据,也可以自己作为主服务器将数据同步给自己的从服务器
命令就是replicaof<目标服务器ip>
那如果主服务器网络波动了一段时间,然后恢复了,此时主服务器和从服务器的命令不保持一致了怎么办呢?
此时redis会使用一个叫增量复制的测率
1.当从服务器恢复网络后会发送一个psync命令给主服务器,此时的psync命令里面的offsite不是-1
2.主服务器在收到该命令之后,然后用CONTINUE相应命令告诉从服务器接下来采用增量复制的方式同步数据
3.然后主服务将从服务器短线这段时间所执行的命令发送给从服务器,然后从服务器执行这些命令
那主服务器怎么知道要发送那些增量数据给从服务器呢


repl_backlog_buffer是一个环形缓冲区,用于主从服务器断联后,从中找到差异的数据
replication offset 标记上面那个缓冲区的同步进度,主服务器用master_repl_offset 来记录写到的位置,从服务器用slave_repl_offset来记录自己读到的位置
主服务器进行命令传播时,不仅会讲命令发送给从服务器还会发到repl_backlog_buffer,因此这个缓冲区会保存着最近的传播的写命令,所以在从服务器发送psync命令之后从服务器将自己的salve_repl_offset发送给主服务器,主服务器根据自己的master_repl_offset 和从服务器的salve_repl+offset来决定用什么方法来传输数据
1.如果需要传输的数据还在repl_backlog_buffer就直接从主服务器进行增量同步的方式
2,如果数据已经和不存在repl_backlog_buffer中,主服务器就选取全量同步的方式
面试结束
小伙子你可以的,什么时候有时间来上班啊,要不明天就来吧?
你强装镇定,这么急啊我还需要租房,要不下礼拜一吧。
好的 心想这小子这么NB是不是很多Offer在手上,不行我得叫hr给他加钱。
能撑到最后,你自己都忍不住自己给自己点个赞了(暗示点赞,每次都看了不点赞,你们想白嫖我么?你们好坏喲,不过我喜欢⁄(⁄ ⁄•⁄ω⁄•⁄ ⁄)⁄)。
总结
在技术面试的时候,不管是Redis还是什么问题,如果你能举出实际的例子,或者是直接说自己开发过程的问题和收获会给面试官的印象分会加很多,回答逻辑性也要强一点,不要东一点西一点,容易把自己都绕晕的。
还有一点就是我问你为啥用Redis你不要一上来就直接回答问题了,你可以这样回答:
帅气的面试官您好,首先我们的项目DB遇到了瓶颈,特别是秒杀和热点数据这样的场景DB基本上就扛不住了,那就需要缓存中间件的加入了,目前市面上有的缓存中间件有 Redis 和 Memcached ,他们的优缺点……,综合这些然后再结合我们项目特点,最后我们在技术选型的时候选了谁。
如果你这样有条不紊,有理有据的回答了我的问题而且还说出这么多我问题外的知识点,我会觉得你不只是一个会写代码的人,你逻辑清晰,你对技术选型,对中间件对项目都有自己的理解和思考,说白了就是你的offer有戏了
————————————————
版权声明:本文为CSDN博主「敖 丙」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_35190492/article/details/102841400
1.Redis数据结构底层实现
https://mp.weixin.qq.com/s/QT69yWu8iswTZGXDLZ0vzQ
2.Redis单线程相关问题
https://mp.weixin.qq.com/s/QT69yWu8iswTZGXDLZ0vzQ
3.Redis有哪些好处(四个好处)
https://mp.weixin.qq.com/s/AqG7bL47cdWYWdcBOyw7WA